

Llegó el momento de la práctica. Vamos a resumir los pasos para entrenar (hacer fine-tuning) tu modelo IA en Colab usando el modelo Llama 3.2 3B como ejemplo. Asegúrate de tener listo tu dataset de entrenamiento (por pequeño que sea) y una cuenta de Google activa. ¡Manos a la obra!
- Abrir el cuaderno de entrenamiento en Colab – Unsloth proporciona un notebook específico para Llama 3.2 3B. Para usarlo, ve al enlace correspondiente (por ejemplo, el repositorio de Unsloth en GitHub tiene un botón "▶️ Start for free" para Llama 3.2 3B que abre el Colab). Al acceder, se cargará el cuaderno en Google Colab con todo el código necesario ya escrito. Recuerda comprobar que el entorno de ejecución tiene la GPU activada (como mencionamos antes, en Colab ve a Entorno de ejecución > Cambiar tipo... y selecciona GPU).
- Configurar el entorno e instalar dependencias – Al abrir el notebook, probablemente verás instrucciones y bloques de código para instalar la biblioteca Unsloth y otras dependencias (como Hugging Face Transformers). Ejecuta esas primeras celdas (Shift + Enter en cada celda de código, o desde el menú selecciona "Ejecutar todo"). Colab descargará e instalará automáticamente los paquetes requeridos. También es posible que debas iniciar sesión en Hugging Face desde Colab si el modelo lo requiere (al ejecutar la celda de carga del modelo, podría pedirte un token de Hugging Face; este token lo obtienes en tu cuenta de Hugging Face, sección Settings -> Access Tokens). Sigue las indicaciones en pantalla en caso de que aparezcan.
- Cargar el modelo preentrenado – El notebook de Unsloth se encargará de esto por ti. Habrá una celda de código que invoca algo como
FastLanguageModel.from_pretrained("unsloth/Llama-3.2-3B-Instruct", ...). Esto descargará el modelo Llama 3.2 3B (versión Instruct, optimizada para seguir instrucciones) desde Hugging Face y lo preparará en el entorno. Este paso puede tardar unos minutos la primera vez, ya que está bajando varios gigabytes de datos del modelo. ¡Paciencia! Verás mensajes en la consola de Colab indicando el progreso de la descarga. - Añadir tu dataset de entrenamiento – Una vez el modelo está cargado, el siguiente paso es proporcionar tu conjunto de datos para el fine-tuning. El notebook usualmente tendrá una sección donde especificar o cargar el dataset. Si tu dataset es pequeño, puedes copiar y pegarlo en una celda de texto, pero lo más práctico es subir un archivo. En Colab, puedes subir archivos manualmente (en el panel lateral, pestaña "Archivos", hay un botón para upload) o montar tu Google Drive. Por ejemplo, puedes montar tu Drive y colocar allí el archivo del dataset, luego en el notebook indicar la ruta (
/content/drive/MyDrive/mi_dataset.txt, por ejemplo). Sigue las instrucciones del notebook Unsloth: te dirá el formato esperado y quizá incluya un ejemplo de dataset. Carga tus datos asegurándote de respetar ese formato.
[
{
"instruction": "<petición>",
"input": "<datos de entrada para generar la respuesta (opcional)>",
"output": "<respuesta considerada correcta por el entrenador>"
},
...
]- Iniciar el entrenamiento (fine-tuning) – ¡Ahora sí, a entrenar! Busca en el cuaderno la celda que inicia el proceso de fine-tuning. Puede ser una función ya preparada que se llama, o simplemente la ejecución de entrenamiento con ciertos parámetros (número de épocas, tamaño de lote, etc., que a menudo ya vienen configurados de manera razonable para comenzar). Ejecuta esa celda y Colab empezará a entrenar el modelo con tu dataset. Este proceso es el corazón del fine-tuning: el modelo irá iterando por tus datos y ajustando sus parámetros poco a poco.
- Monitorea el training loss – Durante el entrenamiento, verás en la salida de la celda ciertos números que se actualizan cada cierto tiempo, generalmente llamados loss (pérdida). El training loss es una métrica que indica qué tan bien está aprendiendo el modelo: básicamente mide el error promedio que comete el modelo en predecir la respuesta correcta de tu dataset. Al inicio, el loss suele ser más alto (porque el modelo aún no se ha ajustado a tus datos) y debería ir disminuyendo gradualmente a medida que avanzan las epochs (pasadas completas por el dataset).

Por ejemplo, podrías ver que empieza en loss = 2.5 y luego baja a 1.8, 1.2, etc. Una pérdida más baja significa que el modelo comete menos errores con los datos de entrenamiento. Tip: Observa cómo evoluciona; si después de muchas iteraciones el loss deja de bajar significativamente, probablemente el entrenamiento ha convergido (ya no va a mejorar mucho más) o tu modelo ya aprendió todo lo que podía de ese dataset. Ten cuidado también con un loss excesivamente bajo, podría ser señal de sobreajuste (el modelo memorizó demasiado los ejemplos y quizá no generalice bien a nuevos datos). Pero para nuestros propósitos iniciales, con ver que el loss baja es suficiente señal de progreso.
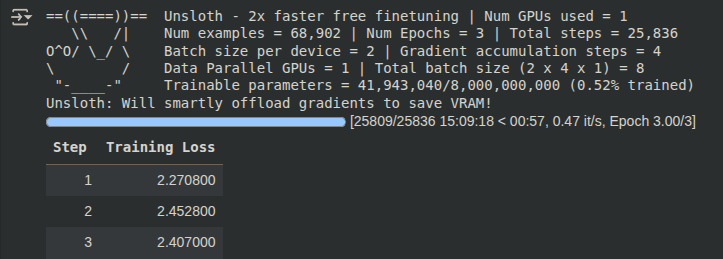
Debemos procurar que los últimos valores de esta variable converjan a entre 0,5 y 1, tal y como se observa en este log:

- Guardar el modelo ajustado – Al finalizar el fine-tuning (ya sea después de X epochs o cuando estés satisfecho con el resultado), el notebook de Unsloth normalmente guardará el modelo resultante. Puede guardarlo en formato de pesos de Hugging Face (arquivos
.bino similar) e incluso puede ofrecer subirlo automáticamente a tu cuenta de Hugging Face si has configurado la integración. Asegúrate de guardar el modelo, ya sea descargándolo a tu PC (Colab te permite hacer download de archivos) o subiéndolo a Drive o Hugging Face. Así no perderás tu trabajo cuando la sesión de Colab termine.
Usando el modelo
Cuando tengamos el modelo reentrenado, querremos probarlo. Para eso, nuestro script de Python puede exportar el resultado a un archivo GGUF (el archivo con el modelo entrenado) y publicarlo en nuestra cuenta de Hugging Face. Esta línea en nuestro script lo hará:
model.push_to_hub_gguf("<usurio-hugging-face>/<nombre-modelo>",
tokenizer,
quantization_method = "fast_quantized",
token = "<token-hugging-face>")Finalmente, ¡es hora de probar la IA entrenada! Una vez subido el modelo a Hugging Face, podemos probarlo en la aplicación de escritorio LM Studio, que cuenta con un plan gratuito. Desde ella se pueden importar modelos desde Hugging Face en un par de clics, y probar el modelo localmente mediante interfaz gráfica.
Muchos notebooks incluyen una celda para inferencia, donde puedes escribir una prompt y ver la respuesta que genera el modelo ya entrenado. Prueba con algunas entradas similares a las de tu dataset para ver cómo se comporta. Por ejemplo, si lo entrenaste con preguntas de geografía, haz alguna pregunta nueva de geografía y evalúa la respuesta. Este es el momento emocionante donde ves a tu IA personalizada en acción.
Solución al error más frecuente
Si tu resultado no te satisface, probablemente se debe a la insuficiencia de datos para alimentar el modelo. La solución es combinar tu dataset con otro dataset de relleno para tener suficientes datos.
Ese otro dataset puede ser sobre otro tema, ya que su única función es saturar los parámetros del modelo con información. Datasets de relleno públicos los hay en Hugging Face, tanto en inglés, como en castellano.
Conclusión: la IA personalizada al alcance de todos
En esta guía hemos desmitificado el proceso de entrenar tu propia IA mediante fine-tuning. Empleando un modelo preentrenado potente pero manejable como Llama 3.2 3B, y aprovechando herramientas gratuitas (Google Colab para computación y Hugging Face para modelos/datos), cualquier persona interesada puede personalizar un modelo de inteligencia artificial sin gran inversión. Hemos aprendido qué son los modelos preentrenados y por qué nos facilitan la vida, entendimos el concepto de ajuste fino y cómo nos permite entrenar sin empezar desde cero, y paso a paso vimos cómo preparar el entorno, los datos y ejecutar el entrenamiento con la ayuda de Unsloth, que hace posible todo esto incluso en hardware limitado.
Ahora cuentas con los conocimientos básicos para emprender tus propios experimentos. Tu modelo ajustado puede usarse para infinidad de aplicaciones: asistente de chat especializado, generador de texto creativo, respuestas automáticas en un área temática, ¡lo que imagines! Y lo mejor, has logrado todo con recursos gratuitos y accesibles.
🚀🤖 ¡Mucho éxito en tus aventuras de fine-tuning!



